Ми раді представити оновлені моделі обробки голосу у сервісі Wyverno Lab.
Відтепер користувачам доступні Wyverno SST v1 Base та Wyverno SST v1 Max — нове покоління моделей, що забезпечує ще вищу якість та точність голосової обробки.
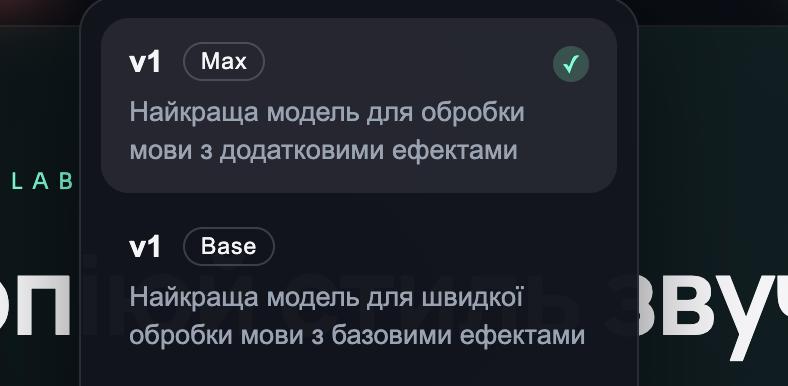
Що нового в оновленні?
-
Покращена архітектура моделей.
Нові версії побудовані з використанням сучасних механізмів Attention, які дозволяють моделям глибше аналізувати референсне аудіо та точніше розуміти його характер. Завдяки цьому ефекти підлаштовуються більш природно й узгоджено з оригінальним звучанням.
-
Більший та різноманітніший датасет.
Моделі були натреновані на значно більшому обсязі даних, що позитивно вплинуло на стабільність результатів, узагальнення та якість обробки в різних сценаріях використання.
-
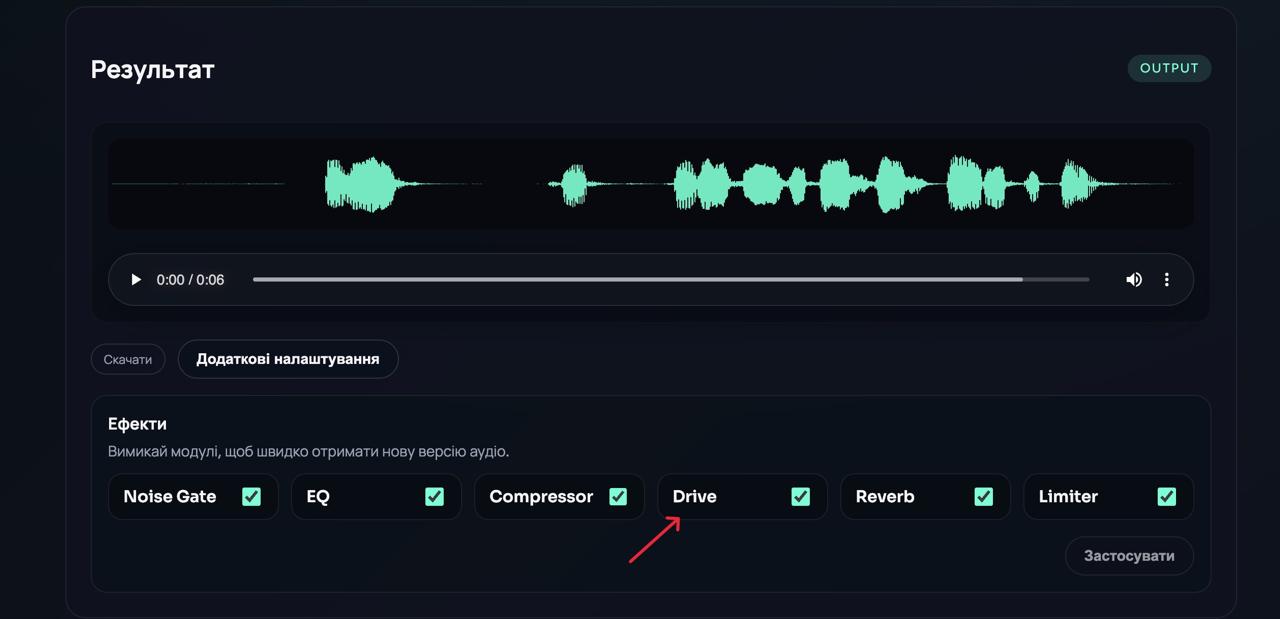
Новий ефект — Drive.
До доступного набору ефектів додано Drive, який розширює можливості тембральної обробки та дозволяє отримувати більш насичене й характерне звучання голосу.
-
Покращення стабільності та виправлення помилок.
Ми усунули низку технічних проблем, зокрема помилку, що виникала під час завантаження файлів з непідтримуваними розширеннями, зробивши сервіс надійнішим і зручнішим у використанні.
Це оновлення — ще один крок у напрямку більш розумної, гнучкої та якісної AI-обробки голосу. Ми продовжуємо активно розвивати Wyverno Lab і вдосконалювати моделі, орієнтуючись на реальні потреби користувачів.