Раді представити бета-версію Wyverno Lab — експериментального сервісу, побудованого на основі сімейства моделей Wyverno, призначених для автоматичного перенесення аудіообробки з одного звукового матеріалу на інший.
Загальна ідея проєкту
Wyverno — це набір нейронних моделей, основною метою яких є відтворення характеру аудіообробки референсного сигналу та застосування цього стилю до нового аудіо без необхідності ручного налаштування ефектів.
Під “стилем обробки” мається на увазі сукупність таких характеристик, як:
• динаміка звучання,
• тембральні особливості,
• просторова обробка,
• загальний характер та “відчуття” звуку.
Модель аналізує готове оброблене аудіо, виділяє його характерні риси та намагається максимально точно перенести їх на вхідний сигнал.
Wyverno Lab як сервіс
На базі моделей Wyverno був створений сервіс Wyverno Lab, який дозволяє:
• швидко виконувати копіювання стилю аудіообробки,
• мінімізувати ручну роботу з ефектами,
• за потреби — коригувати результат шляхом вимкнення окремих ефектів.
Сервіс орієнтований як на технічних користувачів, так і на тих, хто не має глибокого досвіду в аудіоінженерії, але хоче отримати якісний результат.
Концепція Wyverno була запропонована командою Wyverno, відомою своєю роботою над українськими локалізаціями відеоігор та глибоким підходом до якісної аудіообробки й адаптації звучання.
Як працювати з сервісом
Підготовка аудіо
Для початку необхідно підготувати сире (необроблене) аудіо у форматі mp3, wav або ogg.
На даний момент обмежень на тривалість аудіо немає, однак рекомендується НЕ завантажувати файли довші за одну хвилину, оскільки це може впливати на швидкість та стабільність обробки.
Цей файл потрібно завантажити у поле «Файл для обробки».
Підготовка референсу
Далі необхідно обрати референсне аудіо — готовий оброблений звук, стиль якого ви хочете скопіювати.
Для досягнення найкращого результату рекомендується:
• використовувати максимально “чистий” референс,
• уникати сторонніх або зайвих звуків,
• для вокалу — не використовувати аудіо з мінусовками чи фоновою музикою.
Наявність додаткових звуків (наприклад, ударних, тарілок або шумів) може ускладнити аналіз і негативно вплинути на результат, тому бажано попередньо очистити аудіо.
Після цього референсне аудіо потрібно завантажити у поле «Референс стилю».
Вхідне аудіо та референс можуть мати різну тривалість.
Обробка та результат
Після завантаження файлів натисніть кнопку «Скопіювати стиль» та зачекайте завершення обробки.
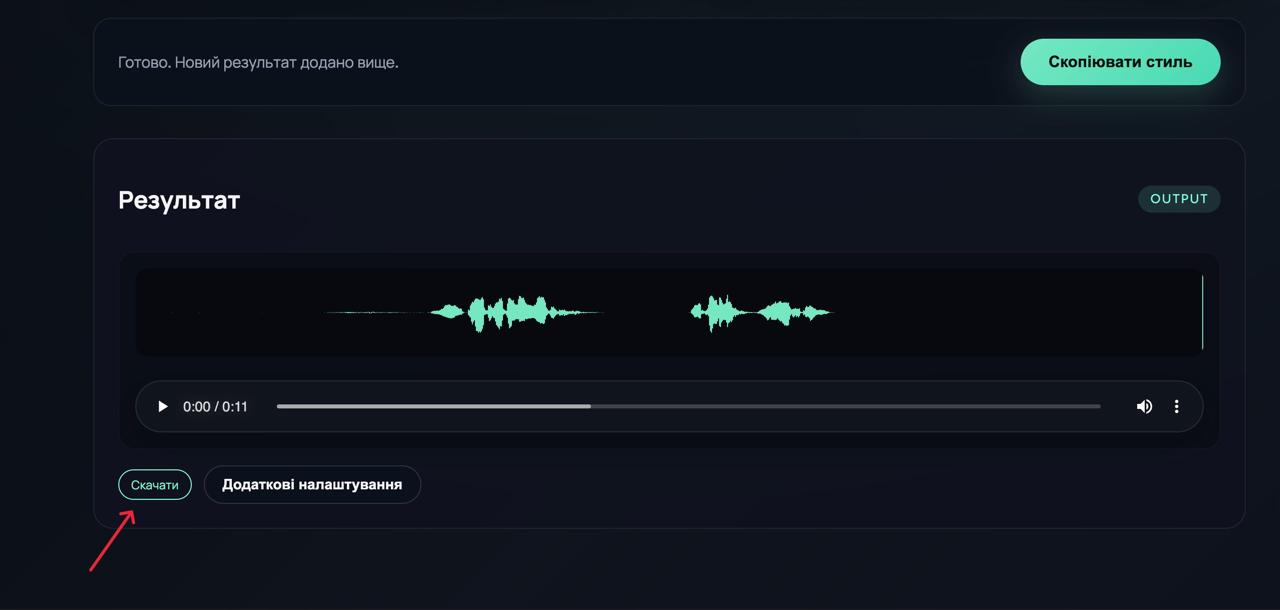
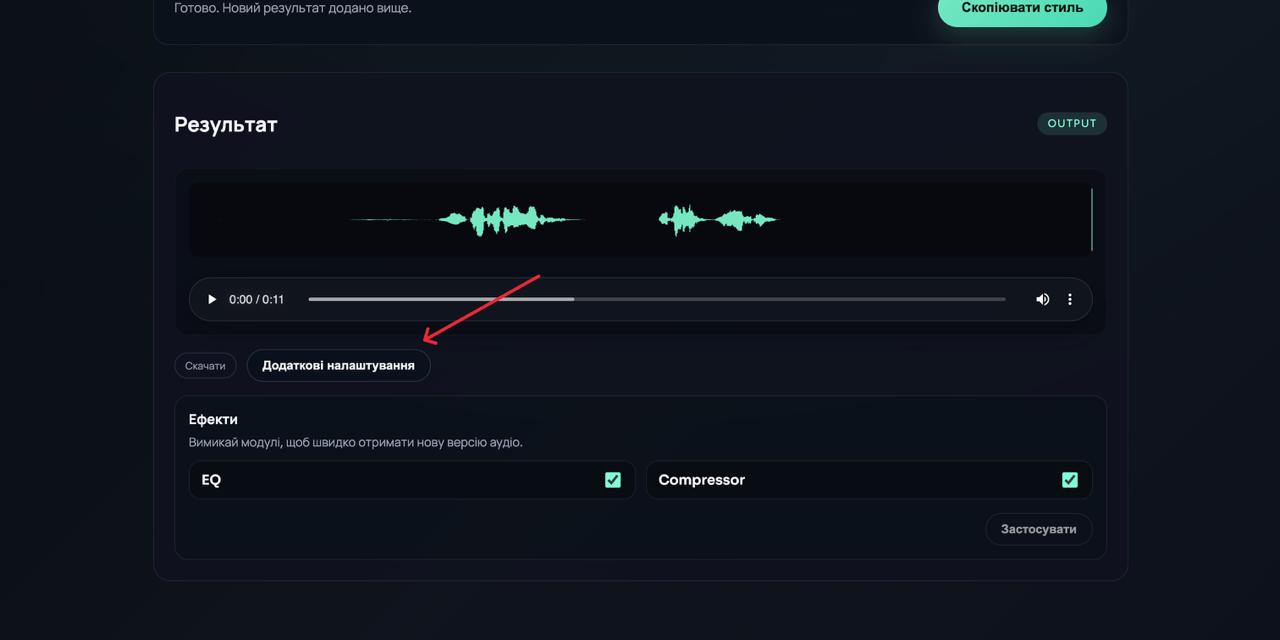
Отриманий результат можна:
• прослухати безпосередньо у сервісі,
• за необхідності — завантажити.
У деяких випадках модель може застосувати зайві ефекти (наприклад, реверберацію там, де вона не потрібна). Для цього передбачено розділ «Додаткові налаштування», де можна вимкнути окремі ефекти та скоригувати фінальне звучання.
Вибір моделі
У Wyverno Lab доступні два типи моделей, залежно від типу аудіо:
Wyverno Speech Style Transfer (Wyverno SST)
Модель, орієнтована на роботу з голосом. Вона дозволяє переносити стиль обробки мовлення — зокрема компресію, еквалізацію та загальний характер звучання голосу.
Wyverno Music Style Transfer (Wyverno MST)
Модель для інструментального аудіо та музичних треків. Її мета — зберегти музичну структуру композиції, водночас відтворюючи стиль звучання референсу.
Рекомендація:
• для голосу — Wyverno SST,
• для інструментів та музики — Wyverno MST.
Версії моделей
Для кожного типу моделей доступні дві версії:
• Base (v0.5)
• Max (v1)
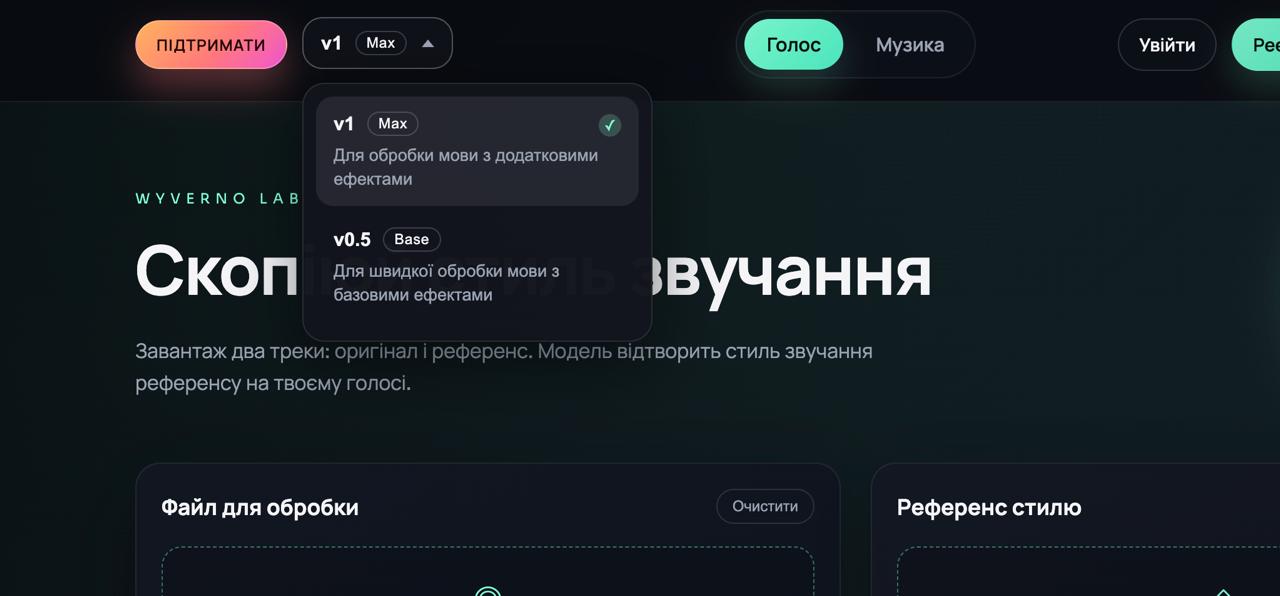
Вони відрізняються кількістю ефектів, які модель може використовувати.
Наприклад, при роботі з голосом:
• Base-версія застосовує лише еквалайзер та компресор,
• Max-версія додатково використовує Noise Gate, Limiter, Reverb та інші ефекти.
Max-версія потребує більше обчислювальних ресурсів і часу, однак на поточному етапі це не є критичним. Тому рекомендується використовувати Max-модель і за потреби вручну вимикати непотрібні ефекти.
Подальші плани розвитку
Wyverno Lab наразі перебуває на ранній стадії розвитку, і попереду заплановано багато покращень, зокрема:
• тренування моделей на більшому обсязі даних для підвищення якості копіювання стилю;
• навчання моделей визначати, чи доцільно застосовувати конкретний ефект, що дозволить автоматично працювати з великою кількістю ефектів;
• розширення списку доступних ефектів, оскільки базового набору може бути недостатньо для складних сценаріїв;
• створення повноцінної панелі керування ефектами, де користувач зможе не лише вмикати або вимикати ефекти, а й змінювати їх параметри.
Реалізація цих ідей можлива лише за підтримки спільноти.
Якщо ви зацікавлені у розвитку проєкту та хочете його підтримати, ви можете зробити це за цим посиланням -> https://donatello.to/HackWhiz